这一系列文章翻译自 Eli Bendersky 的博客,原文地址:https://eli.thegreenplace.net/2020/implementing-raft-part-3-persistence-and-optimizations/,翻译已获得原文作者许可,禁止转载和商用
这是讲解 Raft 一致性协议和 Go 语言实现系列文章的最后一篇,完整的目录如下:
- Part 0: Introduction
- Part 1: Elections
- Part 2: Commands and log replication
- Part 3: Persistence and optimizations (this post)
本文我们会最终完成这个 Raft 库的实现,增加最后需要的持久化功能,并对之前的代码做一些优化。所有的代码都位于这个目录下。
Persistence
像 Raft 这样的共识协议的目的是为了创建一个高可用的系统,方式就是通过在不同节点之间做数据冗余。目前为止,我们关注过像网络分区这样的故障场景,集群中的一些节点可能会跟其他节点断连。另一种故障场景就是机器 crash,例如一个节点重启。
虽然对于其他节点来说,某个节点重启这种现象跟发生网络分区也很相似,都是一个节点短暂地断连了,但对于发生重启的节点自身来说,重启跟断连是完全不同的两种场景,因为重启意味着它存储在易失性存储介质里的数据都丢失了。
Raft 论文中 Figure 2 特意指出了 Raft 算法中所有需要持久化的变量;持久化意味着这个变量每次被更新后状态都需要刷到磁盘上。需要注意的是,Raft 集群中的节点发出下一个 RPC 或答复正在进行的 RPC 之前,任何需要持久化的状态都需要先完成持久化。
Raft 仅需要持久化一些变量就可以,它们有:
- currentTerm:节点最后一次观察到的 term 数值
- votedFor:节点最后一次投票给的目标 peer ID
- log:Raft log
Q:为什么 commitIndex 和 lastApplied 不需要持久化?
A:Raft 可以在重启之后,通过持久化的三个变量确定 commitIndex。每当 leader 确认一条 log entry 被提交后,所有早于这条的 log entry 也都被提交了。当一个 follower crash 后重新启动后,它可以从现在 leader 的 AE 请求中得到正确的 commitIndex。
重启之后 lastApplied 变量归零因为基础的 Raft 算法认为 service(例如一个 kv 数据库)不会保留任何持久化状态。因此它的数据需要通过 Raft log 进行重建。这是很低效的所以存在很多优化的 idea。当 log 越来越多时,Raft 支持 log snapshot 机制生成一个快照。论文中第六节有提到,这超出了这系列文章的内容,如果你感兴趣可以寻找其他博文。
Command delivery semantics
实际情况下,某个指令可能被客户端重复发往 Raft 集群,例如崩溃导致重启,然后重新回放 Raft 日志。
在消息传递语义上,Raft 保证 at-least-once。每当一个指令被提交给 Raft 集群后,最终它会被应用到所有的状态机内,但是有些状态机可能会遇到相同的指令不止一次。因此推荐每个指令携带独一无二的 ID 这样状态机就可以通过 ID 判断哪些指令曾经应用过。这部分内容在论文的第八节。
Storage interface
为了实现持久化,我们新增了下面的接口:
type Storage interface {
Set(key string, value []byte)
Get(key string) ([]byte, bool)
// HasData returns true iff any Sets were made on this Storage.
HasData() bool
}
你可以认为它是一个 map,key 是 string,value 是字节数组。
Restoring and saving state
现在 CM 的构造器里需要包含一个 Storage 变量:
if cm.storage.HasData() {
cm.restoreFromStorage(cm.storage)
}
其中的 restoreFromStorage 也是新出现的,它从存储介质中加载持久化保存的变量,并通过标准库里的 encoding/gob 包进行反序列化:
func (cm *ConsensusModule) restoreFromStorage(storage Storage) {
if termData, found := cm.storage.Get("currentTerm"); found {
d := gob.NewDecoder(bytes.NewBuffer(termData))
if err := d.Decode(&cm.currentTerm); err != nil {
log.Fatal(err)
}
} else {
log.Fatal("currentTerm not found in storage")
}
if votedData, found := cm.storage.Get("votedFor"); found {
d := gob.NewDecoder(bytes.NewBuffer(votedData))
if err := d.Decode(&cm.votedFor); err != nil {
log.Fatal(err)
}
} else {
log.Fatal("votedFor not found in storage")
}
if logData, found := cm.storage.Get("log"); found {
d := gob.NewDecoder(bytes.NewBuffer(logData))
if err := d.Decode(&cm.log); err != nil {
log.Fatal(err)
}
} else {
log.Fatal("log not found in storage")
}
}
与之类似的方法是 persistToStorage,这个方法编码并保存所有需要持久化的变量到存储介质:
func (cm *ConsensusModule) persistToStorage() {
var termData bytes.Buffer
if err := gob.NewEncoder(&termData).Encode(cm.currentTerm); err != nil {
log.Fatal(err)
}
cm.storage.Set("currentTerm", termData.Bytes())
var votedData bytes.Buffer
if err := gob.NewEncoder(&votedData).Encode(cm.votedFor); err != nil {
log.Fatal(err)
}
cm.storage.Set("votedFor", votedData.Bytes())
var logData bytes.Buffer
if err := gob.NewEncoder(&logData).Encode(cm.log); err != nil {
log.Fatal(err)
}
cm.storage.Set("log", logData.Bytes())
}
当这些变量改变时,我们通过调用 pesistToStorage 完成持久化操作。如果你比较过第三篇文章中的 CM 和本节里的 CM 有哪些不同的话,你就会看到这部分代码。
当然这不是做持久化最高效的方式,但它足够简单并且能正确运行。在真正的应用中保存全量的 log 是最低效的行为。为了解决这个问题,Raft 提供了一种 log compaction 机制,论文中第七节提及了。我们不会去实现 log compaction,但你可以自己实现并将它补充进我们的 Raft 库中。
Crash resiliency
持久化实现后,我们的 Raft 集群可以容忍 crash 了。只要集群中不超过半数的 peers crash 或者重启,那么集群就可以对客户端保持可用(如果 leader crash 了的话,新 leader 选举过程中会出现一点延时)。提醒下,一个 2N+1 个节点组成的 Raft 集群可以容忍最多 N 个节点异常。
如果你看过这节的测试代码,你会发现出现了很多新的测试用例。由于我们的集群支持了容错能力,因此可以模拟测试更多故障场景,论文中同样叙述了这部分内容。强烈建议你跑一跑 crash test 并自己观察代码的运行结果。
Unreliable RPC delivery
由于我们本文讲到了加强测试,因此我多提一句,另一种容错测试需要覆盖的就是不可靠的 RPC 请求。到现在为止我们都假设节点之间的 RPC 请求是正常执行的,可能就只有一些延时。如果你阅读 server.go 文件,你会发现它用了 一个名为 RPCProxy 的组件来模拟延时,每个 RPC 请求会延时 1~5ms 来模拟真实环境下同数据中心里节点间的通信。
另一个 RPCProxy 允许我们模拟的是不可靠送达,通过环境变量 RAFT_UNRELIABLE_RPC,一个 RPC 请求可能延时 75ms 或者直接被丢弃,来模拟现实环境中的网络故障。
我们可以用 RAFT_UNRELIABLE_RPC 重新允许测试代码,来观察下 Raft 集群如何应对这些故障。你也可以自己调整 RPCPRoxy 来让它不仅可以模拟 RPC 发送请求,也可以模拟 RPC 响应时的故障。这仅需要增加一点点代码。
Optimizing sending AppendEntries
现在 Leader 的实现有一个很大的缺点,我在第三篇文章中提到过。Leader 通过 leaderSendHeartbeats 方法每隔 50ms 发送 AE 请求。假设一个新的指令发过来,leader 会等到下一次 50ms 的间隔时才会将它告诉给 followers,而不是立即发送给 followers。更糟糕的是,由于使得某个 follower 知道某个指令被提交成功需要两轮 AE RPC 请求,因此这种延时造成的问题会更加突出。下面的图展现了当前有问题的实现方式是如何工作的:
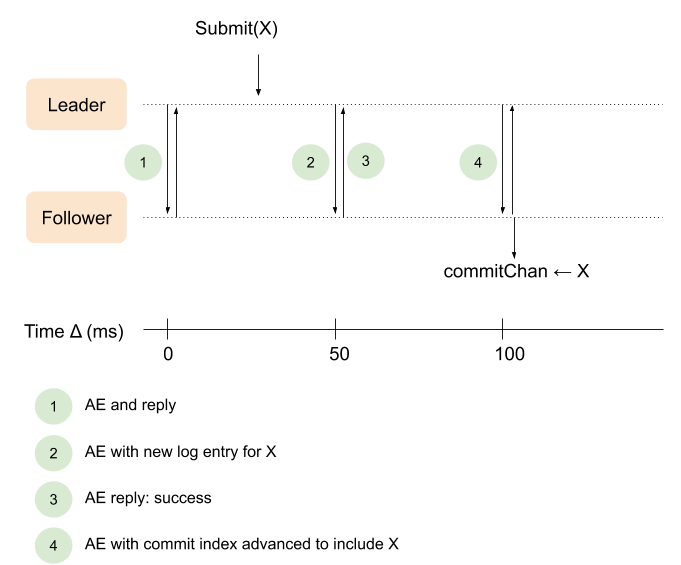
第一步时 leader 给一个 follower 发送了 AE 心跳,不一会儿从 follower 处得到了响应。这时一个新的指令发到了 leader 处,假设是 35ms 时。第二步 Leader 等到 50ms 间隔时才将更新过后的 log entry 发给 follower。
Follower 复制了该指令并成功将其塞到自己的 log 中(此为步骤三)。这时 leader 更新了自己的 commit index(假设它已经收到了多数派的响应)并可以立即通知 follower 该指令可以提交了,但遗憾的是由于心跳间隔是 50ms,因此 leader 还是需要等到下一个 50ms 间隔才能发送附带新的 leaderCommit 的 AE 请求,告诉 follower 某个指令被提交了。
Leader 处的 Submit(X) 方法和 follower 处的 commitChan <- X 两者之间间隔过久,对我们的实现来说是低效的,可以优化。
我们真正希望的响应流程是这样的:
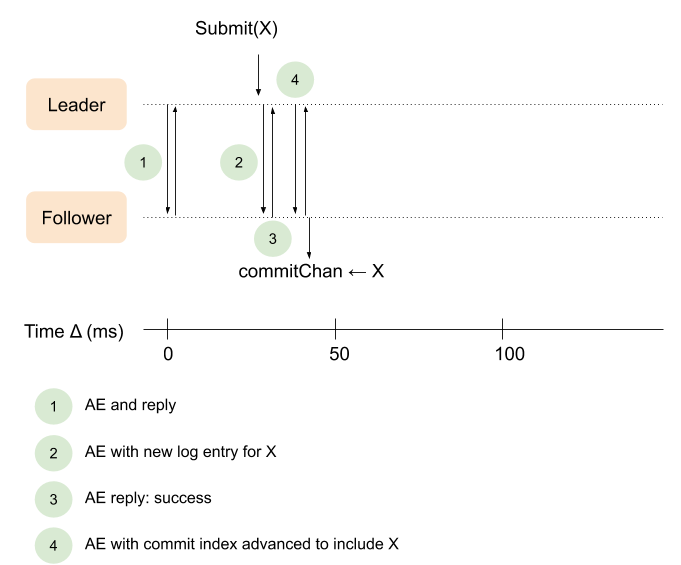
下面的代码即优化了这部分功能。让我们来看看新的实现,还是从 startLeader 方法开始的。不同的行代码我们采用高亮显示:
func (cm *ConsensusModule) startLeader() {
cm.state = Leader
for _, peerId := range cm.peerIds {
cm.nextIndex[peerId] = len(cm.log)
cm.matchIndex[peerId] = -1
}
cm.dlog("becomes Leader; term=%d, nextIndex=%v, matchIndex=%v; log=%v", cm.currentTerm, cm.nextIndex, cm.matchIndex, cm.log)
// 高亮 start
// This goroutine runs in the background and sends AEs to peers:
// * Whenever something is sent on triggerAEChan
// * ... Or every 50 ms, if no events occur on triggerAEChan
go func(heartbeatTimeout time.Duration) {
// Immediately send AEs to peers.
cm.leaderSendAEs()
t := time.NewTimer(heartbeatTimeout)
defer t.Stop()
for {
doSend := false
select {
case <-t.C:
doSend = true
// Reset timer to fire again after heartbeatTimeout.
t.Stop()
t.Reset(heartbeatTimeout)
case _, ok := <-cm.triggerAEChan:
if ok {
doSend = true
} else {
return
}
// Reset timer for heartbeatTimeout.
if !t.Stop() {
<-t.C
}
t.Reset(heartbeatTimeout)
}
if doSend {
cm.mu.Lock()
if cm.state != Leader {
cm.mu.Unlock()
return
}
cm.mu.Unlock()
cm.leaderSendAEs()
}
}
}(50 * time.Millisecond)
// 高亮 end
}
不同于一定需要等待 50ms,现在的 startLeader 方法监听两种事件:
- 发送到 cm.triggerAEChan 这个 channel 里的事件
- 每隔 50ms 触发的定时器
每次从 cm.triggerAEChan 这个 channel 中消费一个事件,就意味着有一个 AE 请求需要立即被发送出去。而每当触发这个事件时计时器都会被重置,这也就意味着如果 leader 没有任何新的 log entry 需要发送,那么最长 50ms 会发送一次心跳 AE。
同时注意,真正发送 AEs 请求的方法重新命名为 leaderSendAEs 而不是之前的 leaderSendHeartbeats,这么做是为了更好地反应我们的编码意图。
触发 cm.triggerAEChan 事件的方法之一,我们应该猜到了,就是 Submit:
func (cm *ConsensusModule) Submit(command interface{}) bool {
cm.mu.Lock()
cm.dlog("Submit received by %v: %v", cm.state, command)
if cm.state == Leader {
cm.log = append(cm.log, LogEntry{Command: command, Term: cm.currentTerm})
cm.persistToStorage()
cm.dlog("... log=%v", cm.log)
cm.mu.Unlock()
cm.triggerAEChan <- struct{}{}
return true
}
cm.mu.Unlock()
return false
}
变化在于:
- 每当一个新指令发送过来,cm.persistToStorage 被调用来持久化新的 log entry。这虽然与心跳优化代码无关,但这里我仍然指出来,因为它在第三篇中并未实现,而是在本篇开头才提及。
- 一个空的结构体发往 cm.triggerAEChan 这个 channel 中,在 leader goroutine 中运行的循环方法会因此改变行为。
- lock 的逻辑也被重新整理了下,我们不希望在发往 cm.triggerAEChan 时还持有锁,因为这可能在某些情况下导致死锁。
你能猜到代码中还有什么地方需要往 cm.triggerAEChan 发送信号么?
答案就是 leader 处理 AE 请求并递增 commit index 的地方。我不会贴出全部的代码,仅有一小部分修改:
if cm.commitIndex != savedCommitIndex {
cm.dlog("leader sets commitIndex := %d", cm.commitIndex)
// Commit index changed: the leader considers new entries to be
// committed. Send new entries on the commit channel to this
// leader's clients, and notify followers by sending them AEs.
cm.newCommitReadyChan <- struct{}{}
cm.triggerAEChan <- struct{}{} // 新增代码
}
这个修改加速了我们的 Raft 算法向 followers commit 新指令的速度。
Batching command submission
上面讲到的代码可能让你觉得不好理解。现在每一次调用 Submit 方法会触发很多行为。如果我们希望一次性向 follower 发送若干条指令怎么办?很可能造成 Raft 集群的网络中会出现陡增的 RPC 请求。
虽然看上去好像不是很高效,但这种方式比较安全。Raft RPC 操作是幂等的,意味着获取相同消息体的 RPC 请求多次实际上没有危害。
如果你对同时提交多条指令导致的 RPC 请求陡增感到担忧,可以优化成批量发送的模式,这个修改也比较简单。实现这种方式的途径可以是修改 Submit 方法,参数可以是一个指令数组。只需要修改少部分代码,就可以实现批量发送指令。你可以自己尝试实现它!
Optimizing AppendEntries conflict resolution
本文中我想讨论的另一个优化是:如果一个 leader 想要让一个 follower 尽快跟上集群复制进度,那么如何减少这个期间被 follower 拒绝的 AEs 次数。回想一下,nextIndex 机制从日志的最末端开始,并且每次 follower 拒绝 AE 时都减一。在极少数情况下,follower 的 log 可能与 leader 差距过大,造成的过程将花费很长时间,因为每个 RPC 往返仅递增一个 log entry。
论文在 5.3 节的末尾提及了针对该场景的优化,但没有提供实现的细节。为了实现它,我们需要在 AE 请求中新增一些属性:
type AppendEntriesReply struct {
Term int
Success bool
// Faster conflict resolution optimization (described near the end of section
// 5.3 in the paper.)
ConflictIndex int
ConflictTerm int
}
两个地方需要修改:
- AppendEntries,AE RPC 的处理方法,每当 follower 拒绝一个 AE 请求时,它会填充 follower 返回的 ConflictIndex 和 ConflictTerm。
- leaderSendAEs,当该方法收到这种被拒绝的 AE 请求时,会通过 follower 返回的 ConflictIndex 和 ConflictTerm 更高效地检索自己的 log,定位到需要同步给 follower 的日志起始位置。
Raft 论文中叙述到:
实践中,我们怀疑这样的优化是否是有必要的,因为 failure 并不经常发生,并且 follower 与 leader 相差非常多 log entry 的情况也比较罕见。
我非常同意,恕我直言,这种情况在现实生活中发生的可能性非常低,并且这种一次获得数百毫秒的优化方式并不能减轻代码的复杂性。 我在这里讲解它只是作为示例,告诉你有很多类似于这样的、可以应用于 Raft 的优化,它们往往是为了解决某些罕见场景而生。 但在编码方面这是一个很好的示例,说明了在某些特殊情况下如何稍微修改 Raft 算法就可以改变行为。
Raft 在设计上,加速了常见的、99% 的业务场景的算法执行速率,但没有过分设计,兼容各种罕见情况作为性能牺牲的代价。 我认为这是绝对正确的设计选择。 例如我们在上一节中叙述的 AE RPC 请求的优化至关重要,因为这种优化确实提升了我们日常场景下的执行效率。
另一方面,上文叙述的 conflictIndex 和 conflictTerm 之类的用于快速回溯 log entry 的优化虽然在技术上确实很有趣,但在实践中我认为并不是非常重要,因为它们在集群生命周期的大多数时间内不会发生,收益很有限。
Conclusion
下面总结下我们的四篇 Raft 实现文章。感谢你们的阅读。
如果对文章内容或者代码有任何疑问,都可以发送邮件给我,或者在 github 上留言 issue。
如果你希望进一步学习工业级的 Raft 实现,我推荐:
- etcd/raft,是一个分布式 kv 数据库
- hashicorp/raft,一个独立的 raft 模块,可以绑定不同的客户端
这些库实现了 Raft 论文中提及的全部特性:
- section 6:集群成员变更管理——如果某个 Raft server 永久下线了,则可以替换该节点保证集群不会停止工作。
- section 7:日志压缩——实际应用中 log 会越来越大,会给持久化和崩溃重建带来麻烦。日志压缩提供了一种日志检查点机制,允许 Raft cluster 高效地复制 log,防止日志体积过大。
Comment