这是 SIGMOD 18 新设的 industry section 收录的一篇来自微软 Azure 团队的论文,主题是通过检测数据(telemetry raw data)来预测数据库是 short-lived(<= 30 天)还是 long-lived(>30天),他们认为理清这个有助于他们了解用户行为和帮助他们进行更好地资源隔离、分配和调度,从而提高收入(我觉得是根本目的吧)。
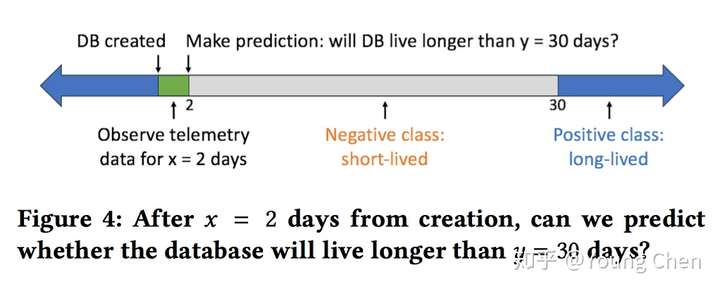
预测的方式是从检测数据中提取特征(features),然后运用机器学习中的随机森林算法(借助 python 的 scikit-learn 来进行分析)。
最开始他们将样本通过地理区域的不同划分为三个 region,然后将每个 region 中包含的数据库划分为三类,Basic、Standard 和 Premium(这部分数据集 80% 为训练集,剩余 20 % 测试集)。
谈到抽取何种 feature,我认为应该是本篇的难点,但是实际上文章只是一带而过,告诉你我们主要有以下 feature:
Creation TimeServer and database namesEdition and performance levelSubscription typeSubscription history
通过分析的结果绘制 KM 生存曲线:
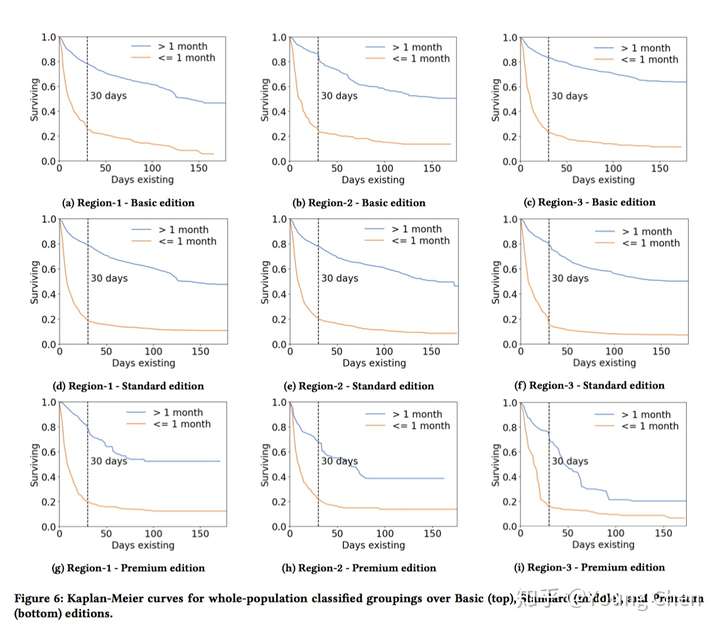
然后是一些置信度计算来说明算法的准确率很高(略过这部分了,本身算法也不是很复杂)
最后,他们得出的结论是:算法的准确率在 90% 以上,他们可以借助结论来规划资源分配和通过资源池对不同类别生存时长的数据库进行资源隔离;而抽取的若干特征中最值得关注的前三位是:
Subscription historyServer and database namesCreation Time
总结下来,论文主要是经验之谈,没什么让人眼前一亮的玩法,优势就在于 Azure 平台有丰富的历史数据可以做这种分析。
License
- 本文遵守创作共享 CC BY-NC-SA 3.0协议
Comment