原文地址:Async IO on Linux: select, poll, and epoll 作者:Julia Evans
虽然一直是个 Java 程序员,但是 select、poll、epoll 这些词汇还是经常听见的,上次写完 UNIX I/O 之后又去再看了一下这部分内容,遇到了这篇文章,感觉不错特此翻译下来,下面是正文。
今天讲一讲我从这本书《The Linux Programming Interface》上学到的三个系统调用:select、poll 和 epoll。
Chapter63:Alternative I/O models
章节内容主要关于当新的数据输入/输出到来时,如何监听如此多的文件描述符呢?谁需要同时关注这么多的文件描述符呢?答案是 Server。
例如,你在 Linux 上用 node.js 写一个 web server,实际上它会使用 epoll 系统调用。让我们谈谈 epoll 和 select、poll 的区别在哪里,和它们是如何工作的。
Servers need to watch a lot of file descriptors
假设你是一个 web server,每次你使用 accept 系统调用接收一个连接时,你会得到一个新的文件描述符来表示那个连接。
作为一个 web server,同一时间你可能有成千上万的连接。你需要知道何时某个连接有新的数据需要发给你,这样你才能处理请求并返回响应。
怎样监听这些文件描述符呢?你可能会用下面的循环方式:
for x in open_connections:
if has_new_input(x):
process_input(x)
上述代码的问题是,它会浪费许多 CPU。与其消耗所有 CPU 时间去询问:“有数据更新么?现在呢?现在呢?现在有么?”,我们还不如直接告诉内核,“现在有 100 个文件描述符,当其中一个有数据更新时通知我。”
有三个系统调用方法可以让你达到告知 Linux 内核去监听文件描述符的目的,它们分别是 poll、epoll 和 select,让我们先从 poll 和 select 开始,因为章节内容就是从他俩先开始的。
First way: select & poll
这两个系统调用在任何 UNIX 系统中都有,而 epoll 是 Linux 独占的。他俩的工作原理是:
- 传给它们一堆等待数据的文件描述符
- 它们会回答你,其中哪个文件描述符对应的数据准备好,可以读写了它们会回答你,其中哪个文件描述符对应的数据准备好,可以读写了
我从书里学到的第一个令人惊讶的事实是,poll 和 select 的代码几乎是相同的!我去看了一下 Linux 内核源码中关于 poll 和 select 的定义之后确信这是真的。
它俩都调用了很多相同的函数,书里特别提到的是 poll 返回了一堆可能的 fd 集合例如:
POLLRDNORM | POLLRDBAND | POLLIN | POLLHUP | POLLERR
而 select 仅仅告知你:
there’s input / there’s output / there’s an error
相比于 poll 返回的更具体的结果,例如 fd 集合,select 仅仅返回粗粒度的信息,例如“你可以读取信息了”。你可以自己阅读这部分功能的具体代码。
我从书中学习到的另一个事实是,在文件描述符稀少的情况下,poll 的性能比 select 更好。为了证明这点,你可以看看 poll 和 select 的方法签名:
int ppoll(struct pollfd *fds, nfds_t nfds,
const struct timespec *tmo_p, const sigset_t
*sigmask)`
int pselect(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, const struct timespec *timeout,
const sigset_t *sigmask);
poll 方法中,你告诉它 “这是我想监听的文件描述符:1,3,8,19 等等” (即是 pollfd 参数)。select 方法中,你告诉它 “我希望监听 19 个文件描述符,我关心其中某个fd的三种(read/write/exception)状态变更(select 使用三个位图来表示三个 fdset)” 所以当 select 运行时,它会轮询这 19 个文件描述符,即使你只关心其中几个。
书中还有许多 poll 和 select 不同的细节,但是这两点是我学到的最主要的。
why don’t we use poll and select ?
但是,我们说了你的 nods.js web 服务器不会使用 select 或者 poll,而是使用 epoll,这是为什么呢?
从书中可得:
每次调用 select 或者 poll,内核必须检查所有上述的文件描述符来发现它们是否准备好了。当监听的文件描述符数量非常多、范围非常大时,耗时就会很夸张、性能自然也不好。
总结看就是内核不会记录它应该监听的文件描述符列表。
Signal-driven I/O (is this a thing people use ?)
书中描述了两种通知内核记录监听文件描述符列表的方式:信号驱动式 I/O 和 epoll。信号驱动式 I/O 让内核在一个文件描述符更新数据时,通过调用 fcntl 返回一个信号给你。我从没听过任何人使用这个,书中叙述看上去就认为 epoll 是更好的,所以我们干脆就直接忽略了,来谈谈 epoll 吧。
level-triggered vs edge-triggered
在我们谈论 epoll 时,我们先来讨论一下 “level-triggered” 和 “edge-triggered” 两种文件描述符通知模式。我之前从没听过这种专业术语(可能来自于电子工程界?)总结起来,接受通知有两种方式:
- 拿到每个可读的且是你感兴趣的 fd 的列表(
level-triggered) - 每当一个 fd 可读时就收到一个通知(
edge-triggered)
what’s epoll ?
好,我们可以来讲讲 epoll 了。我很兴奋,因为之前我浏览代码经常见到 epoll_wait,我经常困惑它到底有什么作用。
epoll 类的系统调用(epoll_create, epoll_ctl, epoll_wait)给予了 Linux 内核文件描述符来跟踪和检查数据更新的功能。
下面是使用 epoll 的步骤:
- 调用
epoll_create告诉内核你将要 epolling 了!它会返回你一个 id - 调用
epoll_ctl来告诉内核你关心哪些文件描述符。有趣的是,你可以传进许多文件描述符(pipes,FIFOs,sockets,POSIX message queues,inotify instances,devices & more),但不是有规律的文件。我觉得是合理的 —— pipes & sockets 的 API 很简单(一个处理对 pipe 的写,一个处理读),所以可以说 “这个 pipe 有新的数据可以读” 。但文件是另类的,你可以朝一个文件的中间写入数据!所以你不能简单的说 “该文件有新的数据可以读取”。 - 调用
epoll_wait来等待你关心的文件有数据更新
performance: select & poll vs epoll
书中有个表格比较了监听十万个操作下的性能优劣:
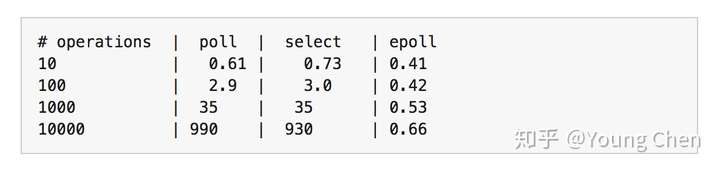
所以当你需要监听大于 10 个 fd 时,使用 epoll 确实会快很多。
License
- 本文遵守创作共享 CC BY-NC-SA 3.0协议
Comment